Vous avez dit "clustering"? L'analyse de données au service de la santé et des performances des vaches
Grâce
à la collaboration transnationale et à la mise en commun de multiples bases de
données, le projet HoliCow brasse un très grand nombre de données et de modèles
de prédictions [1]
acquis
et développés lors de précédents projets
 (voir schéma ci-dessous). L’objectif n’est donc pas de créer de nouveaux modèles mais de combiner
l’information afin d’offrir aux éleveurs une vue holistique de l’état d’une
vache en particulier ou de leur troupeau. Face à toutes ces ressources,
plusieurs étapes ont été nécessaires afin de travailler de manière optimale
pour le développement de l’outil final.
(voir schéma ci-dessous). L’objectif n’est donc pas de créer de nouveaux modèles mais de combiner
l’information afin d’offrir aux éleveurs une vue holistique de l’état d’une
vache en particulier ou de leur troupeau. Face à toutes ces ressources,
plusieurs étapes ont été nécessaires afin de travailler de manière optimale
pour le développement de l’outil final.
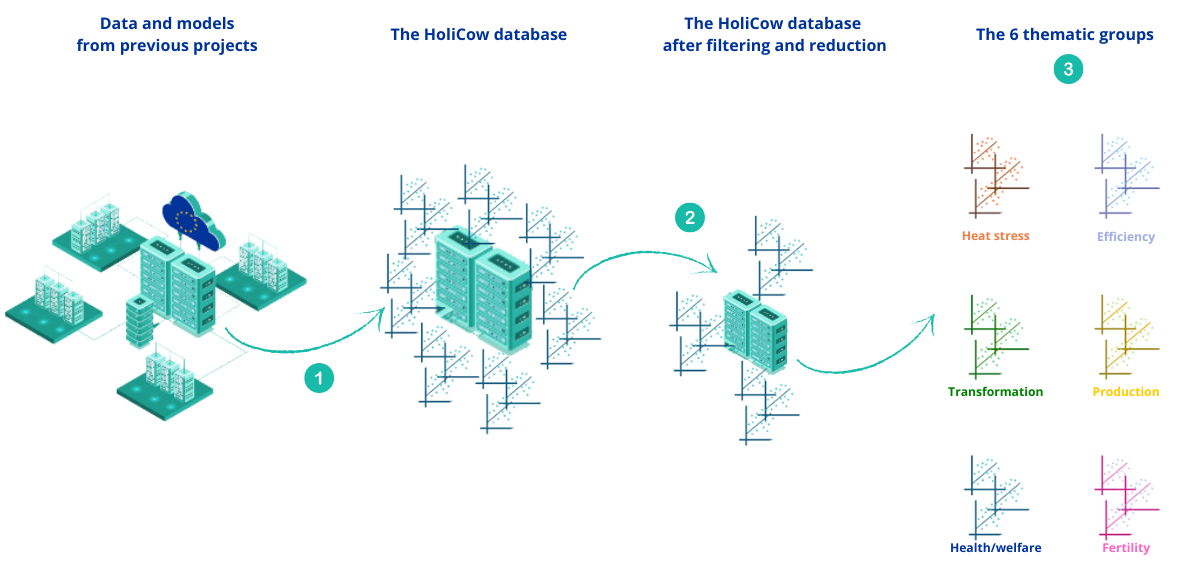
Etape 1: l'écrémage (😉)
Premièrement, un tri  a été
réalisé par les scientifiques afin de garder les modèles les plus pertinents
pour le projet. En effet, dans la mise en commun et l’inventaire réalisés en
début de projet, des redondances étaient observées ou bien plusieurs versions
d’un même modèle [2] étaient présentes.
a été
réalisé par les scientifiques afin de garder les modèles les plus pertinents
pour le projet. En effet, dans la mise en commun et l’inventaire réalisés en
début de projet, des redondances étaient observées ou bien plusieurs versions
d’un même modèle [2] étaient présentes.
Etape 2: le regroupement
Chaque
modèle apporte une information qui lui est propre et qui peut être rattachée à
une thématique spécifique. Par conséquent, après l’écrémage et pour avoir une
vue holistique plus précise, les modèles (et donc les prédictions) ont été
regroupés par thèmes. Ainsi, 6 groupes de travail ont été définis  en fonction de l'information apportée par le modèle:
en fonction de l'information apportée par le modèle: 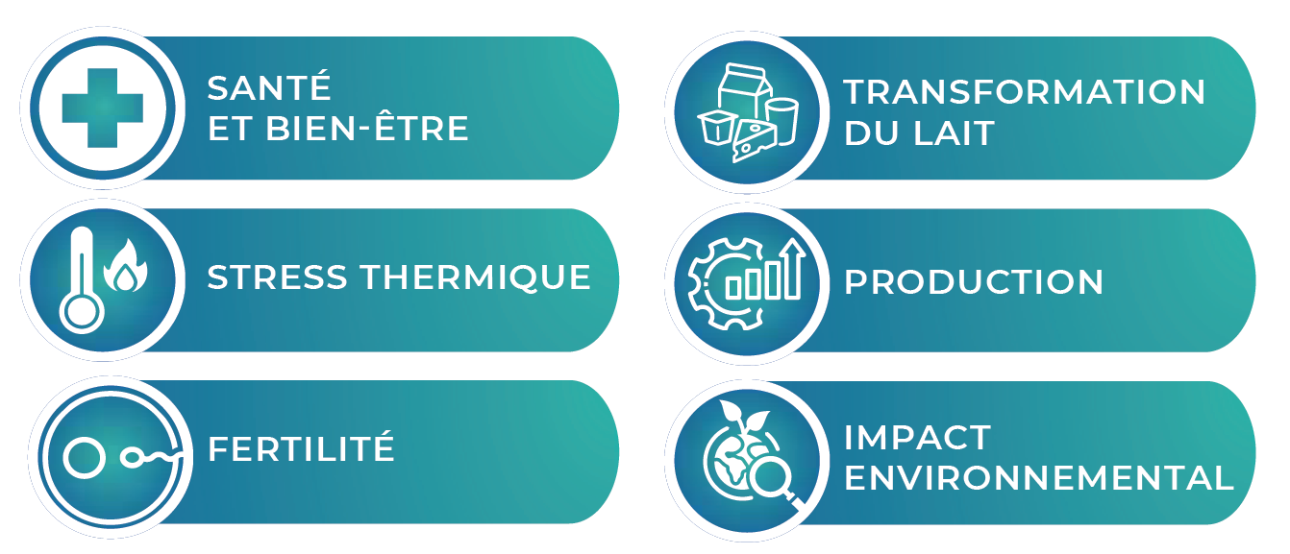
Etape 3: les clusters
Très bien, mais pour chaque thématique, il fallait encore trouver une manière de travailler avec toutes ces données. C’est là que le « clustering » intervient ! Pas de panique, derrière ce terme qui peut paraitre compliqué se cache simplement une technique d’analyse de données permettant de rassembler des individus aux données similaires. Ainsi, ces individus forment un groupe suivant un certain profil de données, ces groupes sont généralement appelés « clusters » par les analystes.
Pour mieux comprendre, prenons un exemple simple : nous observons ci-dessous le groupe thématique « couleur » qui contient le cluster « couleur noire » et « couleur brune ». Nous pouvons dès lors classer nos vaches dans l’un ou l’autre cluster en fonction de la couleur de leur robe. Cependant, cet étiquetage permet uniquement à l’animal d’appartenir strictement à l’un ou à l’autre groupe (c’est ce qu’on appelle la distribution discontinue).
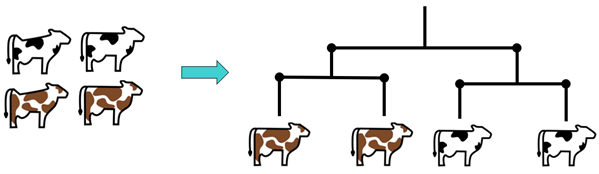
Or dans le projet, il était plus judicieux de travailler avec une distribution continue. En effet, si nous prenons comme exemple le groupe thématique « santé/bien-être », une vache commence par manifester des symptômes et développe une maladie petit à petit. Ou à l’inverse, pendant sa convalescence, elle va de mieux en mieux. C’est donc un processus qui évolue dans le temps. C’est pourquoi nous avons décidé de travailler sur les probabilités d’appartenir à l’un ou l’autre cluster. Si nous reprenons l’exemple du groupe « couleur », nous avons maintenant cette information : « j’ai x% de probabilité d’appartenir au cluster « couleur noire » », ou, dans l’exemple de la vache malade, « j’ai x% de probabilité d’appartenir au cluster « vache malade » ». Ce pourcentage de probabilité variera donc en fonction du stade de la maladie.
Etape 4: vers l'outil
Ces probabilités peuvent donc maintenant être communiquées aux éleveurs pour le guider dans la gestion de son troupeau. Mais comment ? Notre but est que ces résultats de probabilité puissent à la fois être lus à l’échelle intra-troupeau et à l’échelle inter-troupeau. Cela permettra à un éleveur de situer son troupeau par rapport à d’autres. En effet, un pourcentage important ou faible d’animaux pour un certain cluster au sein d’un troupeau donné aura comme conséquence de faire dévier ce troupeau par rapport aux autres.

Conclusion
Chaque groupe thématique est donc défini par plusieurs « clusters ». A ce stade du projet, 4 groupes thématiques ont terminé la partie « clustering » et vont maintenant entrer dans l’étape de validation en fermes pilotes. En effet, il est important et essentiel de passer par cette étape afin de confronter les développements des chercheurs à la réalité du terrain. Un exemple très concret sera par exemple de vérifier si une vache était réellement malade lorsque les résultats prédisaient qu’elle avait une probabilité de l’être. Avec cette étape de validation nous répondons donc à la question :
1. « Tous les clusters d’un groupe thématique sont-ils pertinents à utiliser sur le terrain ? »
2. « Les probabilités qu’a un animal d’appartenir à un cluster collent-elles à la réalité ? »
En répondant à ces interrogations, nous serons alors capables, à l’avenir, de fournir des alertes pertinentes aux éleveurs lorsqu’une vache rencontre des problèmes pour l’une ou l’autre thématique, ou, au contraire, lorsqu’une vache est performante parce qu’elle est susceptible de produire plus ou encore de produire un lait très adapté à la transformation, etc.
Affaire à suivre donc… !
[1] Les modèles de prédictions sont des calculs permettant d’estimer, à partir d’échantillons de lait, le statut de la vache sur de multiples aspects (ex. : estimation des minéraux, d’acides gras, corps cétoniques, émissions de méthane…)
[2] Un modèle peut se voir évoluer au cours du temps pour, par exemple, devenir plus robuste grâce à l’acquisition de nouvelles données.